In the Fall of 2019 I moderated a panel on crowdsourcing:
“Our closing point was: if you get others’ data, use it only for the intended use case. And as Megan reminds us, “be sure the intended use case is clear; “consent” doesn’t mean anything if people don’t understand what they’re opting into. And if it changes, that’s okay! Just let people know and require them to consent again.”And now from the July 12, 2023 Insider:
The proposed class-action lawsuit, filed by Clarkson Law Firm in the US District Court for the Northern District of California on Tuesday, accused Google, AI sister company DeepMind, and parent company Alphabet of taking people’s data without their knowledge or consent.
“Google has taken all our personal and professional information, our creative and copywritten works, our photographs, and even our emails — virtually the entirety of our digital footprint” to build its AI products, the lawsuit claims.
Category / technology
Best Places To Work
I’ve worked on employer branding at Schwab, Mozilla and continue to support it within Salesforce‘s technology org. Some core employer brand programs I’ve ran include entering employer ratings competitions (I have some issues with these but they are certainly a proxy), managing Glassdoor ratings, and getting general coverage and endorsements for being a great employer.
So when I saw this CNBC coverage of Hubstaff as a Top Remote employer, I was intrigued and, as many would, headed over to Glassdoor to hear what employees were saying directly.
It was here that I encountered perhaps a closer real-world analogy to this beloved @DPRK_News account than the real deal: an HR response to this employee’s review on Glassdoor (screenshots for posterity):

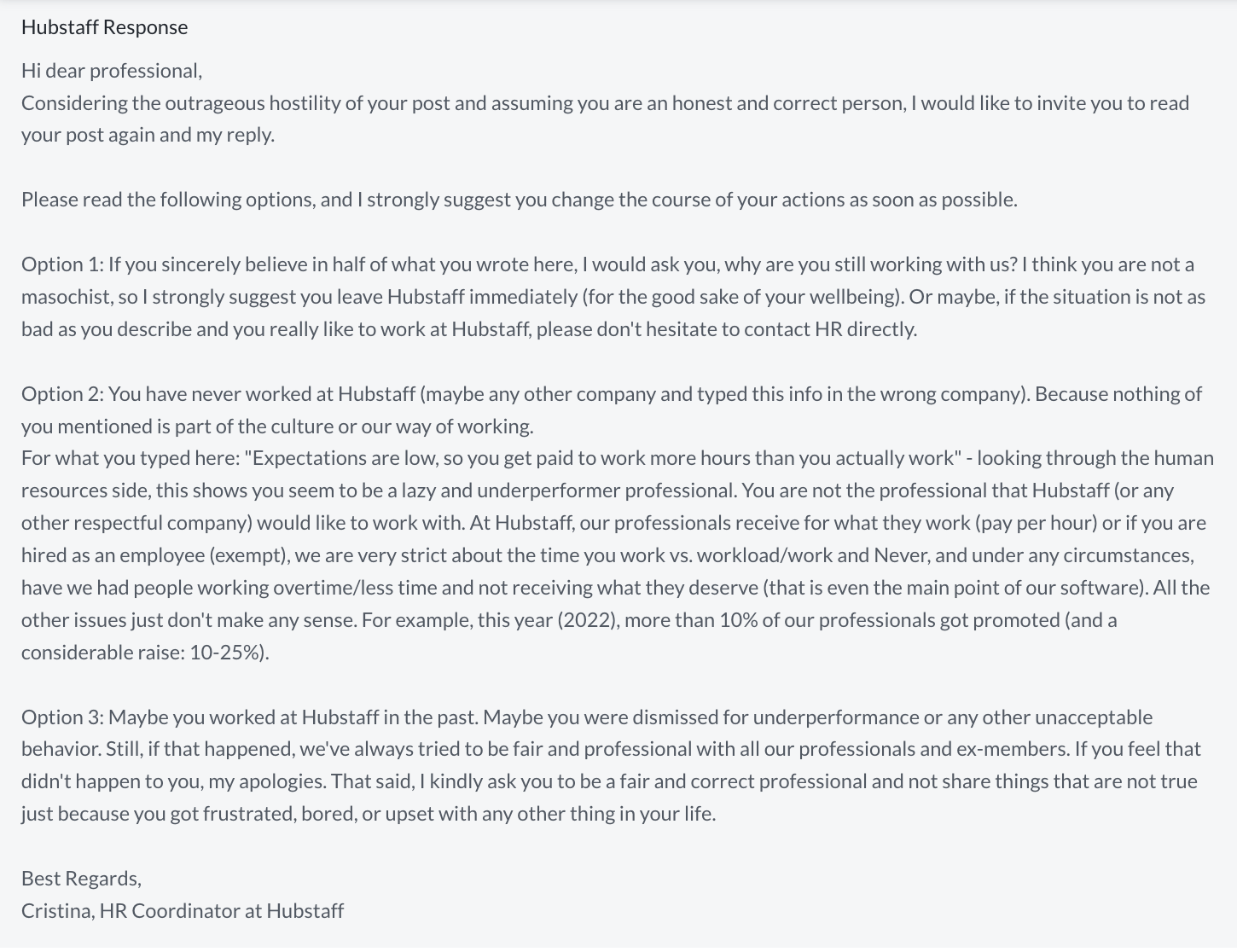
Do not Link
Unsurprisingly, the enterprise which commodified endorsements continues its profitable human engineering. The latest discovery: training humans to dig down for the thing they want, rather than simply offering it to them.
The reason any self-respecting UX professional would diminish these natural human tendencies is the 2010s most notable invention: growth marketing. It all becomes normal once we are trained.
This may explain this enterprise’s fondness for the producer of the Turk and the Warehouse.